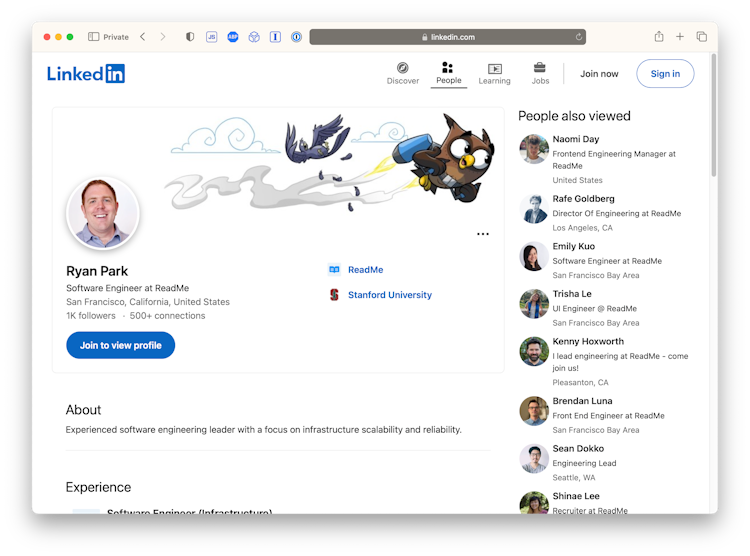
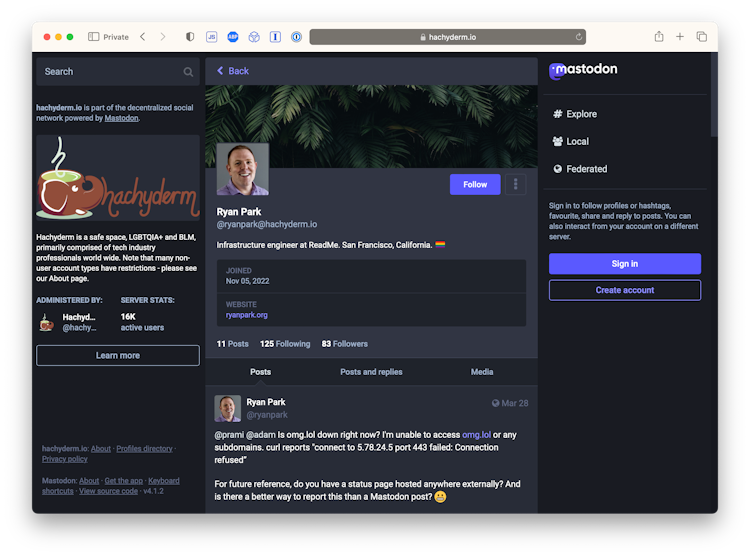
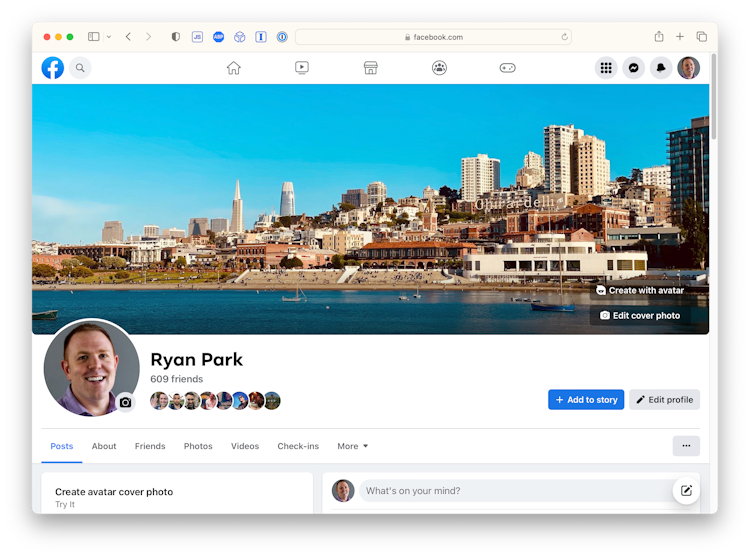
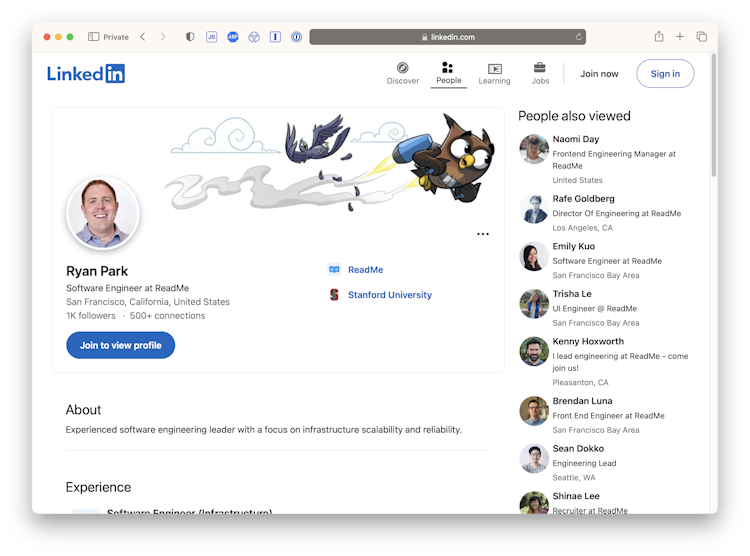
I’m an Infrastructure Engineer at ReadMe in San Francisco. (he/him)
I’ve worked at Stripe, Slack, Runscope, and Pinterest, as an infrastructure engineer and manager.
Before that I attended Stanford University and George Washington University.
I’m originally from Bettendorf, Iowa.